
Stable Diffusion Web UIで高解像度の画像を生成したいとき、生成する画像のサイズを上げると、絵が破綻することが多いと思います。これは、画像生成モデルの学習元の画像のサイズと生成する画像のサイズがかけ離れていることが原因だと思われます。
そこで今回は、Stable Diffusion Web UIで生成した512×512の画像を高解像度化する方法の解説と、その方法による違いを比較検証していきたいと思います。
グラフィックボードの性能が足りない方は、この機会に是非グレードアップを検討してみてください。
◆ AI画像生成の入門モデルとしておすすめのグラフィックボード
◆ ワンランク上のハイエンドモデルとしておすすめのグラフィックボード
◆ 最高峰の超ハイエンドモデルとしておすすめのグラフィックボード

◆ Stable Diffusion AI画像生成ガイドブック

Stable Diffusion Web UIの高解像度化の機能
Stable Diffusion Web UIには、高解像度化するための機能として以下のものがあります。
・Hires. fix (高解像度補助)
・Extrasのアップスケール
それぞれ使ってみて結果をお見せしたいと思います。
比較対象元となる高解像度化前の画像(512×512)はこちらです。

Hires. fix (高解像度補助)を使用する
Stable Diffusion Web UIでは、高解像度化するための様々な手法を選択することができます。
まずは、手法(Upscaler)毎の特徴を見ていきましょう。
| Upscaler | 生成画像 |
|---|---|
| Latent | 画像の解像度を高めるための技術の一つですが、画風にも影響を与えることがあります。 入力された元画像の潜在空間を拡大して、txt2imgで再生成するという方法のため、Denoising strengthを高めに設定しないとノイズが残る傾向があります。他のアップスケーラーと比較すると、Latentはディテールが豊かで色味が鮮やかな画風になりやすいですが、元画像から変化する部分が多くなることもあります。 イラストやアニメ風の画像に向いています。 |
| Lanczos | 画像の縮小リサイズに向いている補間メソッドです。 Sinc関数を用いて、画像の周波数成分を低域に限定することで、画像の鮮明さを保ちつつ、ノイズやエイリアスを抑える効果があります。lobeというパラメータで波の広がりを調整できる特徴があります。lobeの値が大きいほど、画質が向上しますが、処理が重くなります。 写真や風景などの自然な画像に向いています。 |
| Nearest | 画像の拡大や縮小において、隣り合うピクセルの色をそのままコピーする補間メソッドです。 処理が最も速く簡単なメソッドですが、画質が劣化しやすく、ジャギーや偽色が発生する欠点があります。 ドット絵やパレット画像など、色の変化が少なく、ピクセルの形が重要な画像に向いています。 |
| ESRGAN_4x | 画像の拡大リサイズに向いている補間メソッドです。 Enhanced Super-Resolution Generative Adversarial Networks (ESRGAN)という敵対的生成ネットワーク (GAN)を用いて、画像の高解像度化を行う技術です。画像の細部やテクスチャを鮮明に再現し、リアルな画質を実現する効果があります。 イラストやアニメなどの画像に向いています。 |
| LDSR | Deep Laplacian Pyramid Super-Resolutionの略で、画像の超解像に用いられる深層学習アルゴリズムです。 画像の高周波成分を復元するためにラプラシアンピラミッドを用いるという特徴があります。高精度、高効率という利点があります。 イラストやアニメなどの画像に向いています。 |
| R-ESRGAN 4x+ Anime6B | Real-ESRGANという画像の超解像に用いられる深層学習アルゴリズムの一種です。 4x+は、4倍の拡大率、Anime6Bは、Anime6Bというモデルを使用することを表しています。 画像の細部や色彩を綺麗に復元することができるという特徴があります。 アニメやイラストなどの画像に向いています。 |
| ScuNET | Swin-Conv-UNetという画像のノイズ除去に用いられる深層学習アルゴリズムの一種です。 Swin-Convブロックという局所的なモデリング能力と非局所的なモデリング能力を持つブロックを用いて、UNetというエンコーダー・デコーダー構造を構築しています。実際の画像に含まれる様々な種類のノイズを除去することができるという特徴があります。 写真や動画などの画像に向いています。 |
| ScuNET PSNR | ScuNETの一種で、PSNRという画質評価指標を最大化するように学習されたモデルです。 ScuNETと比べて、画像の細部や色彩をより忠実に復元することができるという特徴があります。 写真や動画などの画像に向いています。 |
| SwinlR_4x | SwinIRという画像の超解像に用いられる深層学習アルゴリズムの一種で、4倍の拡大率を持つモデルです。 Swin TransformerというTransformerベースのブロックを用いて、画像の特徴を階層的に抽出することができるという特徴があります。 写真や動画などの画像に向いています。 |
Upscalerの選択以外では、Hires stepsとDenoising strength(ノイズ除去強度)というパラメータがあります。
まずはこの2つの適正範囲を検証していきたいと思います。
Hires steps
Hires stepsは0~150まで選択でき、デフォルトは0になっています。
倍率を2倍にして、アップスケーラをデフォルトのLatentに固定、またDenoising strengthもデフォルトの0.7に固定して、ステップ数を(0,10,15,20,35,50,100,150)にして比較してみます。
また、高解像度化にかかる時間も比較してみます。


ステップ数を最大まで上げても絵が破綻することなく、上げれば上げるほど、より鮮明な画像になりました。グラボのスペックが高ければ、できるだけ上げた方が良い結果になりそうです。
高解像度化にかかる時間は次のようになりました。
(512×512の画像生成にかかる時間は差し引いています)
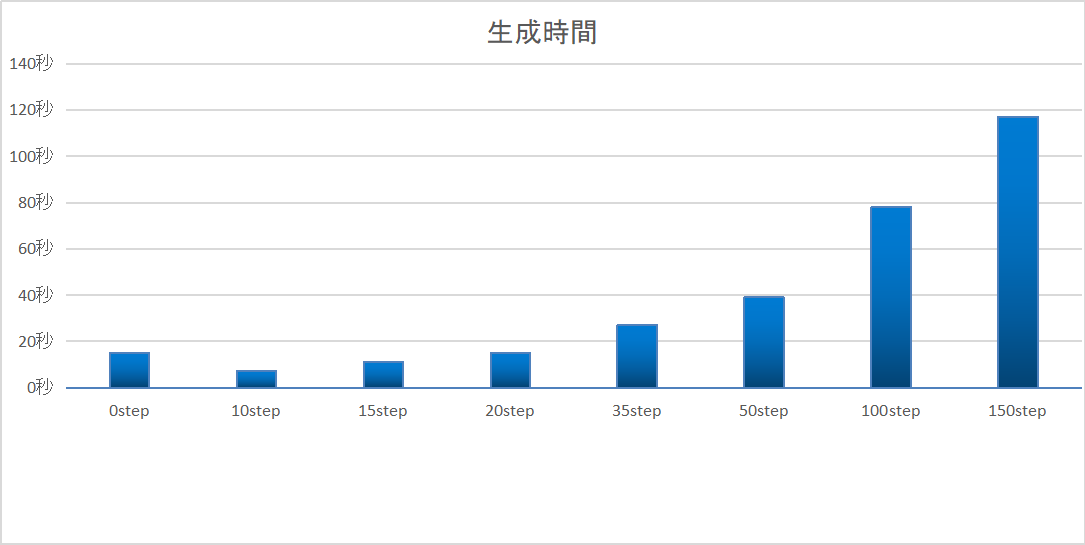
0stepは20stepと同じ時間がかかりました。
512×512の画像生成のときのSampling stepsが20だったので、Hires stepsを0にした場合は、それを引き継いでいるのだと思われます。
0step(Sampling stepsと同じステップ数=20step)でも十分に綺麗に高解像度化されました。
より鮮明な画像にしたい場合は50step、もしくは最大値の150まで引き上げてしまって良いと思います。
Denoising strength(ノイズ除去強度)
Denoising strength(ノイズ除去強度)は0~1まで設定可能で、デフォルトは0.7になっています。
倍率を2倍にして、アップスケーラをデフォルトのLatentに固定、またHires stepsもデフォルトの0に固定して、Denoising strengthを0から0.1刻みで比較してみます。



0.6あたりから十分な鮮明さがあり、0.9以上は完全に構図が変わってしまいました。
まとめると以下のような特徴がでました。
・値が小さいほど、構図が変わりにくいがぼやける。
・値が大きいほど、鮮明になるが構図が変わりやすくなる。
アップスケーラとの組み合わせにもよると思いますが、0.6~0.8の範囲で良い塩梅を見つけるのが良さそうです。Hires stepsは構図への影響が無かったので、Denoising strengthを決めてから鮮明さをHires stepsで調整するのが良いのではないでしょうか。
また、Denoising strengthは画像の生成時間には影響ありませんでした。
Upscaler毎の生成画像の比較
Hires stepsは0固定にして、Upscaler毎の違いを比較します。
| Upscaler | 生成画像 |
|---|---|
| Latent |  |
| Latent (antialiased) |  |
| Latent (bicubic) |  |
| Latent (bicubic antialiased) |  |
| Latent (nearest) |  |
| Latent (nearest-exact) |  |
| None |  |
| Lanczos |  |
| Nearest |  |
| ESRGAN_4x |  |
| LDSR | Errorになりました。。。 |
| R-ESRGAN 4x+ |  |
| R-ESRGAN 4x+ Anime6B |  |
| ScuNET |  |
| ScuNET PSNR |  |
| SwinlR_4x |  |
どれもそれ程大きな違いは出ませんでしたが、個人的にはScuNET PSNRが良さそうに見えます。
高解像度化にかかる時間は次のようになりました。
(512×512の画像生成にかかる時間は差し引いています)
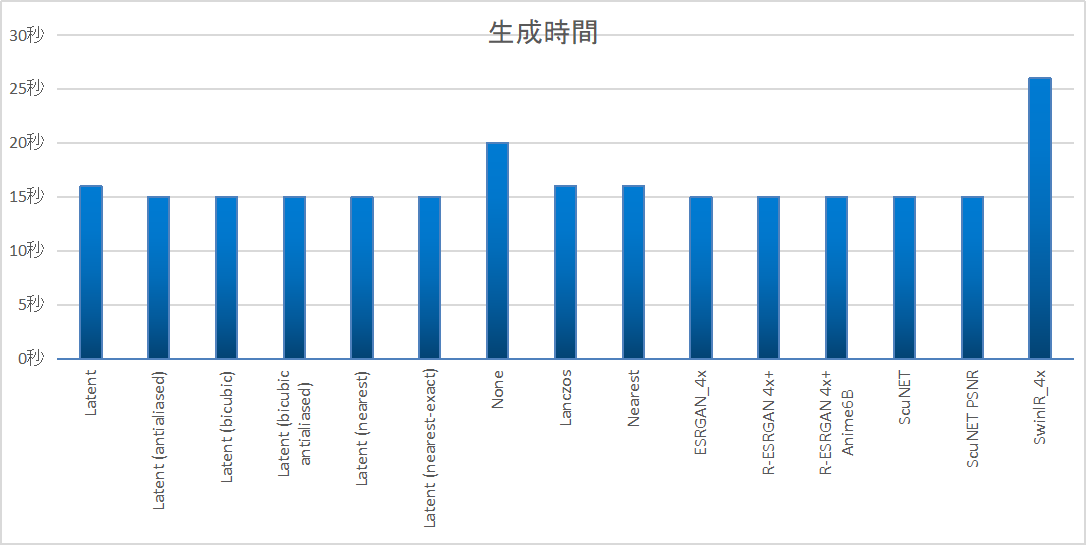
どのUpscalerを選んでも鮮明に高解像度化できますが、どうしても元の画像から構図が少し変わってしまいます。
Extrasのアップスケールを使用する
次にExtrasのアップスケール機能を使って高解像度化してみます。
Extrasのアップスケールでは次のパラメータがあります。
・Upscaler 1
・Upscaler 2
・Upscaler 2 visibility
・GFPGAN visibility
・CodeFormer visibility
・CodeFormer weight (0 = maximum effect, 1 = minimum effect)
GFPGAN visibilityの設定値による出力の差異
GFPGAN visibilityは、顔面修復のアルゴリズムを適用する度合いを調整するパラメータです。
GFPGANは、顔を綺麗にすることができるモデルで、人物や動物の顔に対して有効です。
GFPGAN visibilityは、0~1までの値で設定でき、0はGFPGANを適用しないことを意味し、1は最大限に適用することを意味します。GFPGAN visibilityを高くすると、顔がより鮮明になります。
Upscaler 1をScuNET PSNRに固定して、GFPGAN visibilityを0から0.1刻みにして比較します。
→ほとんど変わらなかったので0と1のみ比較します。
左が0で、右が1です。


CodeFormer visibility
CodeFormer visibilityは、CodeFormerというTransformerベースの顔面修復アルゴリズムを適用する度合いを調整するパラメータです。
CodeFormerは、GFPGANの代替としての顔復元ツールで、古い写真の修復に有効です。
CodeFormer visibilityは、0から1までの値で設定でき、0はCodeFormerを適用しないことを意味し、1は最大限に適用することを意味します。CodeFormer visibilityを高くすると、顔がより鮮明になります。
Upscaler 1をScuNET PSNRに固定して、CodeFormer visibilityを0,0.5,1.0にして比較します。



→古い写真の復元用なので、もともとある程度鮮明なイラストの高解像度化では全然使えません。
CodeFormer weightはCodeFormer visibilityの影響度を調整するパラメータですが、今回は検証不要ですね。
Upscaler1と2を使って比較する
左から順番に、以下の設定でアップスケールした画像を比較します。
・Upscaler1=設定なし。Upscaler2=設定なし。
・Upscaler1=ScuNET PSNR。Upscaler2=設定なし。
・Upscaler1=ScuNET PSNR。Upscaler2=R-ESRGAN 4x+ Anime6B。Upscaler 2 visibility=0.1。
・Upscaler1=ScuNET PSNR。Upscaler2=R-ESRGAN 4x+ Anime6B。Upscaler 2 visibility=0.5。
・Upscaler1=ScuNET PSNR。Upscaler2=R-ESRGAN 4x+ Anime6B。Upscaler 2 visibility=1.0。





少しずつ鮮明になっていってますが、やりすぎるとクッキリしすぎて違和感が出てきます。
まとめ
Hires.fixを使った方法、Extrasのアップスケールを使った方法、それぞれのパラメータを変えて比較しましたが、いかがでしたでしょうか?
構図が少し変わることを許容できるなら、Hires.fixを使用したアップスケールがおすすめです。
構図を絶対に変えたくない場合は、少しぼやけますがExtrasのアップスケールを使用することをおすすめします。
個人的には、Hires.fixでアップスケーラをScuNET PSNRにして、Denoising strengthを0.6~0.8の範囲で調整後、Hires stepsをMAXにして(ここはマシンスペックと相談して)アップスケールするのが良いと思いました。Hires stepsは20でも十分ですが。
他にも良い設定や方法があれば、是非コメントで教えてください。
グラフィックボードの性能が足りない方は、この機会に是非グレードアップを検討してみてください。
◆ AI画像生成の入門モデルとしておすすめのグラフィックボード
◆ ワンランク上のハイエンドモデルとしておすすめのグラフィックボード
◆ 最高峰の超ハイエンドモデルとしておすすめのグラフィックボード
◆ Stable Diffusion AI画像生成ガイドブック








コメント